|
|
Recently, artificial (AI) algorithms have become widely popular and have significantly changed fields ranging from business analytics to healthcare. AI is a concept that refers to any technique that enables computers to mimic human behaviour. Machine learning is a subset of AI. Machine learning refers to giving computers the ability to perform tasks without human intervention.
Let's consider an example where machine learning can be implemented. Let's suppose we want to classify the emails into promotional or non-promotional emails. If we were to solve this using computer programming, we would have to write a program that uses certain hard-coded rules or conditional if-else statements in a program to check if the email contains words like "Discount", "Sales", "Gift", "Free item", .etc. There is a problem with that computer program. It is impossible to come up with all the words that will classify an email into promotional and non-promotional. This is where we can implement machine learning. Machine learning can identify unique attributes that can classify the email. We have to implement a specific machine learning algorithm that can be called a model. We will pass the data into our newly created model, and it will classify the email as promotional or non-promotional.
Let's understand some terms related to machine learning.
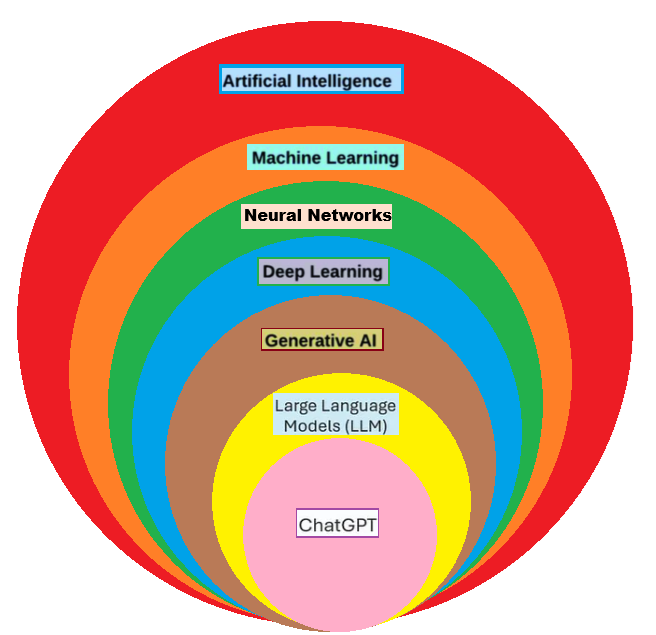
Artificial Intelligence:The phrase "artificial intelligence" (AI) encompasses a wider range of technologies that allow machines to think like the human brain, solve problems, and make decisions without the need for human assistance. They are capable of handling both easy and extremely difficult tasks.
Machine learning:Machine learning is a branch of artificial intelligence that focuses on teaching machines to identify patterns in data and progressively improve their performance. Instead of creating every rule by hand, machine learning systems use algorithms to evaluate data, find patterns, and produce predictions.
Neural Networks:The human brain, the most intricate structure in the universe, serves as an inspiration for neural networks. First, let us examine how the brain functions. Neurons are the basic building blocks of the human brain. The most fundamental computing unit in every neural network, including the brain, is a neuron. Up until the processed output reaches the Output Layer, neurons take input, process it, and then forward it to other neurons in the network's several hidden levels.
Deep Learning: While traditional machine learning (ML) relies on algorithms and human-engineered features for simpler, structured data, requiring less computation but more initial effort, deep learning (DL), a specialized subset of Neural Networks, uses multi-layered artificial neural networks (ANNs) to automatically learn complex patterns from enormous amounts of raw data. Consider machine learning (ML) as a toolbox for learning from data, and deep learning (DL) as a potent, sophisticated tool inside that box, perfect for jobs like image/speech recognition but requiring more power and data.
Generative AI: Generative AI is a form of artificial intelligence capable of producing original text, images, music, and even code. It generates outputs that often closely resemble human-created content. This is achieved through advanced techniques such as deep learning and neural networks.
LLM: Large Language Models (LLMs) are advanced machine learning systems developed using extensive amounts of textual data, enabling them to generate and comprehend language in a manner similar to humans. They are capable of handling various natural language processing tasks, including text generation, sentiment analysis, and summarization.
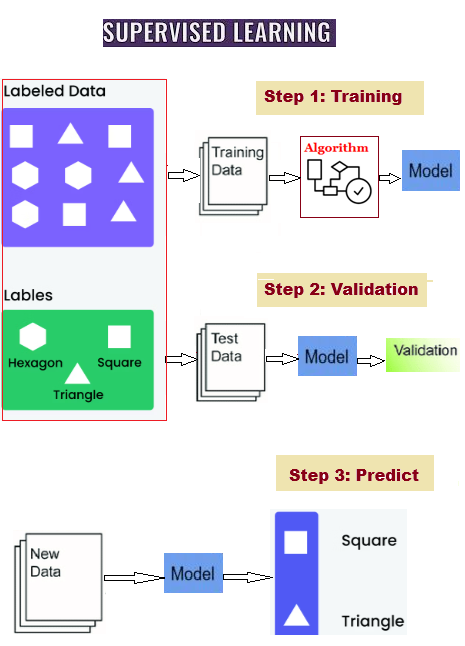
The process of training a model on a "Labeled Dataset" is known as supervised learning. Both input and output parameters are present in labelled datasets. Algorithms in supervised learning acquire the ability to map points between inputs and accurate outputs. Both training and validation datasets are labeled.
Supervised learning is used for two main kinds of problems.- Classification and Regression.When a model is trained using supervised learning, the data is split into two parts in an 80:20 ratio. 80% of the data is used to train the model, and the other 20% is used to test it. While training, both the input and the correct answer are provided to the model for 80% of the data. The model learns by looking at this training data.
| Linear regression | Logistic Regression |
| Polynomial regression | Naive Bayes |
| Decision Trees | Decision Trees |
| Random Forests | Random Forests |
| Support Vector Machine(SVM) | Support Vector Machine(SVM) |
| K-Nearest Neighbors | K-Nearest Neighbors |
| Gradient Boosting | Gradient Boosting |
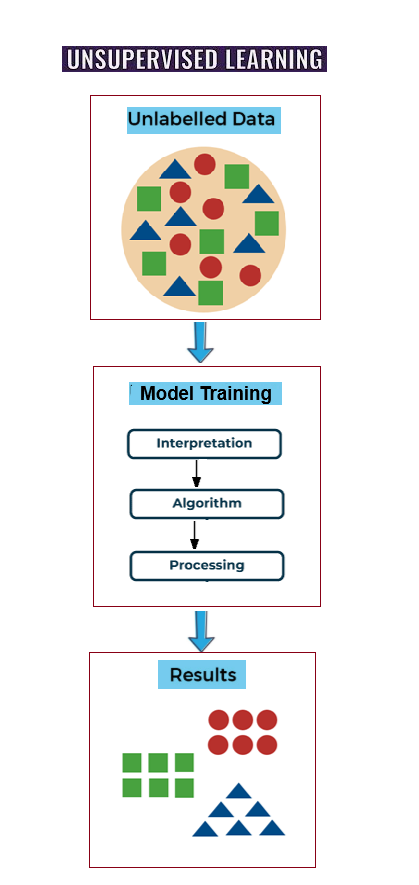
Since unlabeled data is used in unsupervised learning, there are no predetermined results. The program independently identifies linkages, groups, and hidden patterns in the data. Data visualization, dimensionality reduction, and clustering are its primary applications. It is frequently used in fraud detection, recommendation systems, and marketing, where patterns are more important than labels.
Machine learning algorithms, also known as self-learning or algorithms, are trained on unlabeled data sets—that is, input data that has not been classified—in unsupervised learning. The appropriate algorithms are selected for training based on the tasks, or machine learning problems like associations, clustering, etc., and the data sets
The algorithms learn and deduce their own rules throughout the training phase based on the similarities, patterns, and contrasts of the data points. The algorithms do not require pre-training or labels (goal values) in order to learn. A machine learning model is the result of this algorithm's training process using data sets. The model is an unsupervised machine learning model since the data sets are unlabeled (no target values, no human supervision). The model is now prepared to carry out unsupervised learning tasks including dimensionality reduction, grouping, and association. Complex tasks, such as clustering huge datasets, are well suited for unsupervised learning models.
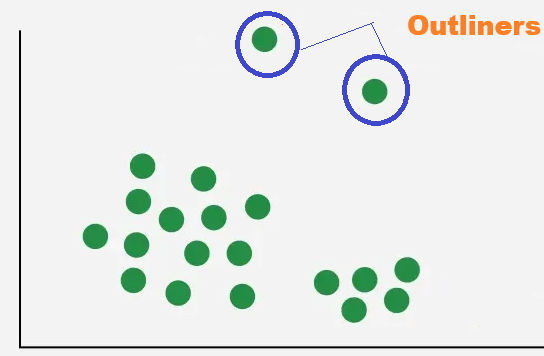
Outliers in machine learning are those data points that very much differ from the dataset's overall distribution. They could be the result of uncommon occurrences, natural variance, or mistakes in data gathering. Outlier detection is an important preprocessing step because, although they can occasionally provide valuable insights, such as in fraud detection, they frequently have a detrimental impact on model accuracy and skew findings..
1. Global Outliers:
Bias
When a machine learning model is overly simplistic and fails to extract sufficient information from the data, bias occurs. It is similar to thinking that all birds can only be small and fly; as a result, the model becomes biased in its predictions and is unable to identify large birds like penguins or ostriches. Although these presumptions facilitate training, they may hinder the model's ability to fully capture the intricacies of the data.
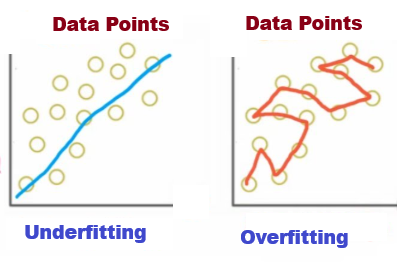
Underfitting, where the model performs badly on both training and testing data because it does not learn enough from the data, is usually caused by high bias.
Variance
A statistical measure of how far a set of data deviates from its mean is called variance. A large variance implies that the data is widely spread, whereas a low variance shows that the data points are closely packed around the mean. It is computed by averaging each data point's squared deviations from the mean. A high-variance model has poor generalization on new data because it learns both the patterns and the noise in the training set. Overfitting, in which the model performs well on training data but badly on testing data, is usually caused by high variance.
Noise in machine learning refers to random or irrelevant data that can lead to unexpected circumstances that deviate from our expectations. Inaccurate measurements, erroneous data collecting, or irrelevant information are the causes. Noise can obscure links and patterns in data, much as background noise can obscure speech. For accurate modeling and forecasting, handling noise is crucial. Strong algorithms, data purification, and feature selection are some of the techniques that mitigate its consequences. Ultimately, noise reduction increases the effectiveness of machine learning models.
Overfitting
When a model learns too much from the training data—including irrelevant characteristics like noise or outliers—it is said to be overfitting.
Consider fitting a complex curve to a group of points, for instance. Although the curve will pass through each point, it will not accurately depict the pattern.
Because of this, the model performs exceptionally well on training data but poorly on fresh data.
Overfitting models are comparable to pupils who remember solutions rather than comprehending the subject. They perform well on practice exams (training) but find it difficult to pass actual exams.
Causes of Underfitting
1. Excessive Model Complexity: Training data, including noise, can be more easily memorized by models with an excessive number of parameters or layers.
2. Overtraining (Too Many Epochs): If a model is trained for an extended period of time, it may eventually begin to learn the noise in the data, which may deteriorate its performance on new data.
3. Noisy or Irrelevant Features: The model may focus on the incorrect signals if the data contains a lot of irrelevant information.
Underfitting
The opposite of overfitting is underfitting. It occurs when a model is too basic to adequately represent the data.
Consider, for instance, fitting points that genuinely follow a curve with a straight line. The majority of the pattern is missed by the line.
In this instance, the model performs poorly on both training and testing data.
Underfitting models are similar to understudied students. They perform poorly on both practice and actual exams. It should be noted that the underfitting model has low variance and high bias.
Causes of Underfitting
1. The model may not be able to capture the complexity of the data because it is too simplistic.
2. The underlying causes impacting the target variable are not adequately represented by the input characteristics used to train the model.
3. The training dataset's size is insufficient.