|
PythonPlaza -
Python & AI
|
Supervised Machine Learning Algorithms
K-Nearest Neighbors
Although it can be applied to regression tasks, K-Nearest Neighbors (KNN) is a supervised machine learning technique that is mostly employed for classification. It produces predictions based on the average value (for regression) or the majority class (for classification) after locating the "k" nearest data points (neighbors) to a given input. KNN is an instance-based and non-parametric learning technique since it does not assume anything about the distribution of the underlying data.
K-Nearest Neighbors is also known as a lazy learner algorithm because, rather than learning from the training set right away, it retains the dataset and acts upon it during classification.
MAE (Mean Absolute Error) quantifies the average magnitude of errors for KNN regression.
Mean Absolute Error
It calculates the average discrepancy between a dataset's actual and forecasted values. Without taking direction into account, it displays the deviation between predicted and actual values.
1. Determined by utilizing absolute differences
2. Easy to calculate and understand
3. Handles every mistake equally
4. Not as susceptible to significant errors as MSE
5. Frequently employed to assess regression models

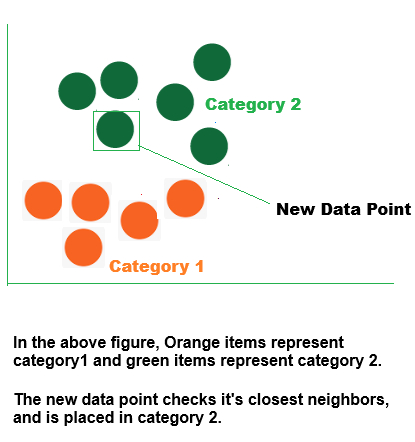
What does "K" stand for in "K Nearest Neighbor"?
The number k in the k-Nearest Neighbors method simply indicates how many neighboring points or points the algorithm should consider while making a conclusion.
For instance, let us say you are determining the type of fruit based on its size and shape. You make comparisons to familiar fruits.
•The algorithm examines the three fruits that are closest to the new one if k = 3.
•The algorithm determines that the new fruit is a mango because the majority of its neighbors are mangos if two of those three fruits are mangos and one is a banana.
Euclidean Distance
Euclidean distance is the most common distance metric used in KNN. For two points, (x1, y1) and (x2, y2), the Euclidean distance is:
√((x2 - x1)² + (y2 - y1)²).
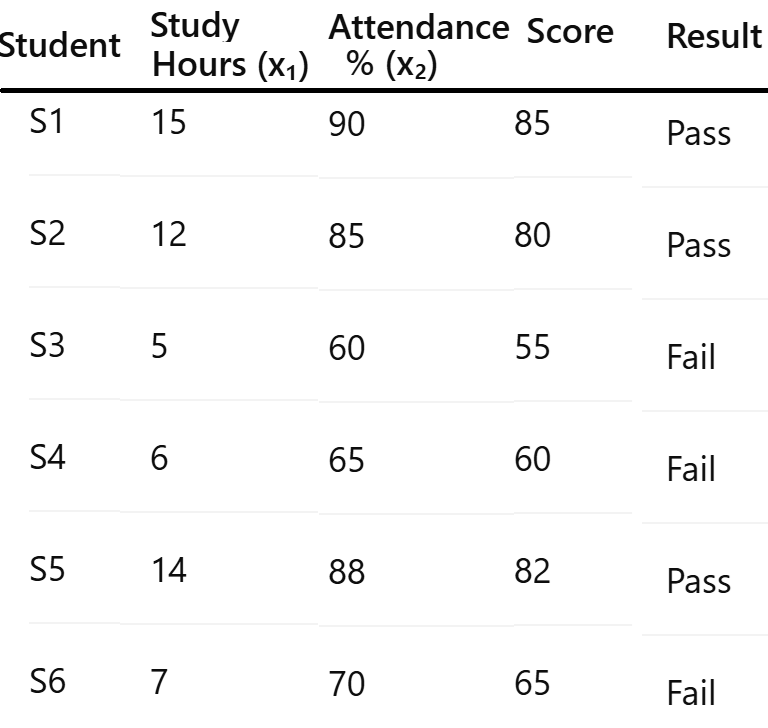



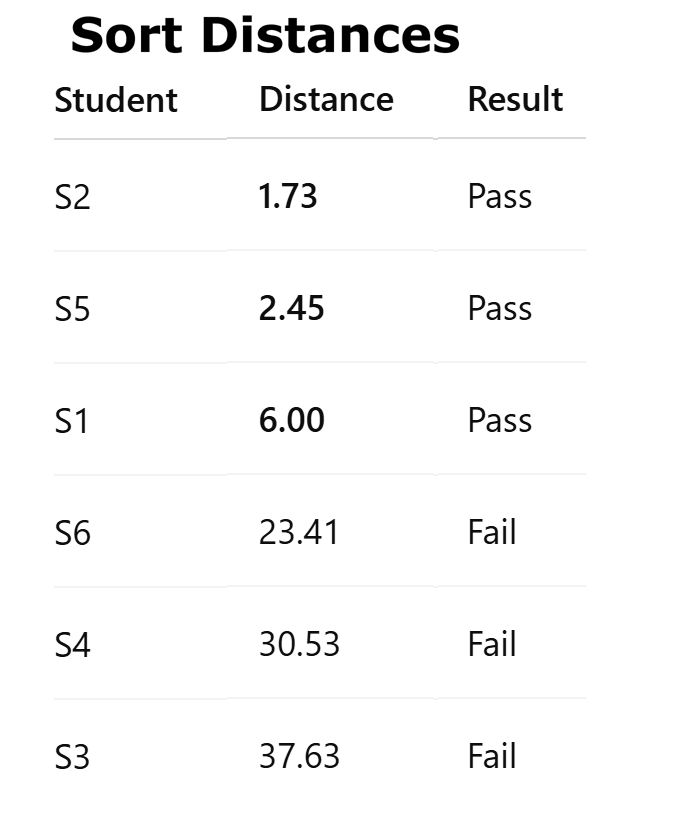

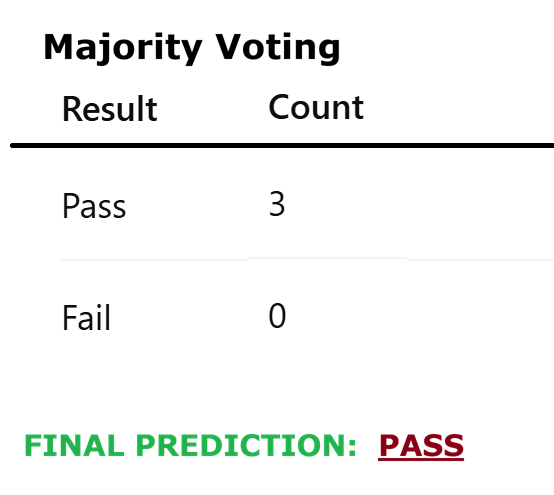 USE CASE 1: Using K-Nearest Neighbors with scikit-learn, predict the product price. The Production cost, Advertising spend, and Demand level are the independent variables.
USE CASE 1: Using K-Nearest Neighbors with scikit-learn, predict the product price. The Production cost, Advertising spend, and Demand level are the independent variables.
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, r2_score
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
data = pd.read_excel("product_data.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target
# -----------------------------------
X = data[['Production_Cost', 'Advertising_Spend', 'Demand_Level']]
y = data['Product_Price']
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
Step 4: Build KNN pipeline (scaling + model)
# -----------------------------------
model = Pipeline([
("scaler", StandardScaler()),
("knn", KNeighborsRegressor(
n_neighbors=5,
weights="distance",
metric="minkowski"
))
])
# -----------------------------------
Step 5: Train the model
# -----------------------------------
model.fit(X_train, y_train)
# -----------------------------------
Step 6: Make predictions & evaluate
# -----------------------------------
y_pred = model.predict(X_test)
print("MAE:", mean_absolute_error(y_test, y_pred))
print("R² score:", r2_score(y_test, y_pred))
# -----------------------------------
#Step 7. Predict price for a new product
# -----------------------------------
new_product = pd.DataFrame({
'Production_Cost': [68],
'Advertising_Spend': [13],
'Demand_Level': [37]
})
predicted_price = model.predict(new_product)
print("\nPredicted Product Price:", predicted_price[0])
USE CASE 2: Using K-Nearest Neighbors with scikit-learn to predict the Student Grade. The 'Hours_Studied, 'Attendance_%', 'Previous_Score' are the independent variables.
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, r2_score
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
# https://pythonPlaza.com/linear_school_grade_data.html
data = pd.read_excel("student_data.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target
# -----------------------------------
X = data[['Hours_Studied', 'Attendance_%', 'Previous_Score']]
y = data['Final_Grade']
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
Step 4: Build KNN pipeline (scaling + model)
# -----------------------------------
model = Pipeline([
("scaler", StandardScaler()),
("knn", KNeighborsRegressor(
n_neighbors=5,
weights="distance",
metric="minkowski"
))
])
# -----------------------------------
Step 5: Train the model
# -----------------------------------
model.fit(X_train, y_train)
# -----------------------------------
Step 6: Make predictions & evaluate
# -----------------------------------
y_pred = model.predict(X_test)
print("MAE:", mean_absolute_error(y_test, y_pred))
print("R² score:", r2_score(y_test, y_pred))
# -----------------------------------
#Step 7. Predict
# -----------------------------------
Example: Predict a new student’s grade
# New student: [hours_studied, attendance %, previous_score]
new_student = np.array([[6, 85, 78]])
predicted_grade = model.predict(new_student)
print("Predicted final grade:", predicted_grade[0])
USE CASE 3: Using K-Nearest Neighbors with scikit-learn to predict the Profit Optimization. The Price (P), Advertising (A), Units Sold (Q) are the independent variables, and Profit is the dependent variable.
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, r2_score
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get the Profit Optimization data in Excel
data = pd.read_excel("profit_optimization.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target Price (P)
# -----------------------------------
X = data[['Price', 'Advertising', 'Units_Sold']]
y = data['Profit']
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
Step 4: Build KNN pipeline (scaling + model)
# -----------------------------------
model = Pipeline([
("scaler", StandardScaler()),
("knn", KNeighborsRegressor(
n_neighbors=5,
weights="distance",
metric="minkowski"
))
])
# -----------------------------------
Step 5: Train the model
# -----------------------------------
model.fit(X_train, y_train)
# -----------------------------------
Step 6: Make predictions & evaluate
# -----------------------------------
y_pred = model.predict(X_test)
print("MAE:", mean_absolute_error(y_test, y_pred))
print("R² score:", r2_score(y_test, y_pred))
# -----------------------------------
#Step 7. Predict
# -----------------------------------
#Predict profit for a new business strategy
# Example: Price = 15, Advertising = 165, Units Sold = 460
new_strategy = np.array([[15, 165, 460]])
predicted_profit = model.predict(new_strategy)
print("Predicted profit:", predicted_profit[0])
USE CASE 4: Using K-Nearest Neighbors with scikit-learn to predict the Patient Response. The Dosage (mg), Age (yrs), Weight (lbs) are the independent variables, and Patient Response is the dependent variable.
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, r2_score
# -----------------------------------
#Step 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get the Patient Response Data in Excel
data = pd.read_excel("patient_dosage_response.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
#Step 2. Define features and target Price (P)
# -----------------------------------
X = data[['Dosage', 'Age', 'Weight']]
y = data['Patient_Response']
# -----------------------------------
#Step 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
Step 4: Build KNN pipeline (scaling + model)
# -----------------------------------
model = Pipeline([
("scaler", StandardScaler()),
("knn", KNeighborsRegressor(
n_neighbors=5,
weights="distance",
metric="minkowski"
))
])
# -----------------------------------
Step 5: Train the model
# -----------------------------------
model.fit(X_train, y_train)
# -----------------------------------
Step 6: Make predictions & evaluate
# -----------------------------------
y_pred = model.predict(X_test)
print("MAE:", mean_absolute_error(y_test, y_pred))
print("R² score:", r2_score(y_test, y_pred))
# -----------------------------------
#Step 7. Predict
# -----------------------------------
Predict response for a new patient
# New patient: Dosage=72mg, Age=36yrs, Weight=172lbs
new_patient = np.array([[72, 36, 172]])
predicted_response = model.predict(new_patient)
print("Predicted patient response:", predicted_response[0])
About Us | Contact Us | Sitemap | Privacy Policy